Artificiell intelligens (AI) utvecklas i rasande fart, och i framkanten av denna revolution hittar vi Large Language Models (LLMs). Men vad är egentligen en LLM? Den här artikeln ger en detaljerad LLM förklaring och utforskar hur dessa kraftfulla AI-modeller fungerar, från deras grundläggande arkitektur till deras imponerande förmåga att generera text och förstå språk. Vi kommer att dyka ner i hur de tränas, vilka användningsområden de har och vilka utmaningar som finns med denna spännande teknologi.
Innehållsförteckning
ToggleVad är en Large Language Model (LLM)?
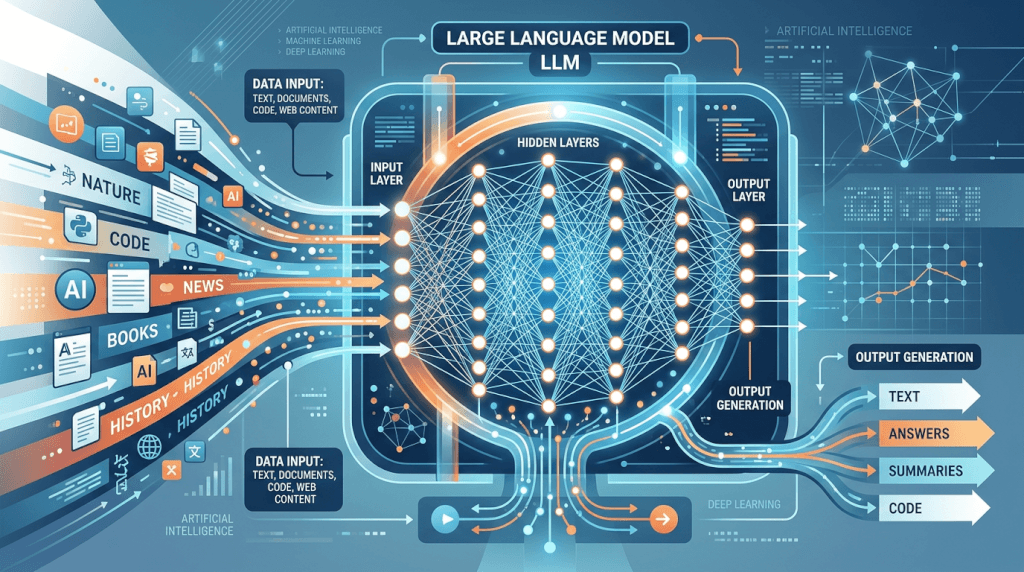
En Large Language Model (LLM) är en typ av AI-modell som är designad för att förstå och generera mänskligt språk. De är tränade på enorma mängder textdata, vilket gör att de kan lära sig komplexa mönster och relationer i språket. Tänk dig att mata en dator med hela internet – det är ungefär den storleken på datamängder som används för att träna LLMs.
Dessa modeller använder sig av neurala nätverk, särskilt transformer modeller, för att bearbeta och generera text. Genom att analysera miljarder ord och fraser kan LLMs förutsäga nästa ord i en sekvens, svara på frågor, översätta språk och till och med skriva olika typer av kreativt innehåll.
Kort sagt, en LLM är en avancerad form av generativ AI som kan förstå och generera text på ett sätt som liknar mänsklig kommunikation.
Nyckelkomponenter i en LLM
- Neurala Nätverk: Grunden för LLMs, inspirerade av strukturen i den mänskliga hjärnan.
- Transformer Modeller: En specifik arkitektur av neurala nätverk som är särskilt effektiv för att hantera sekvensdata som text.
- Träningsdata: Enorma mängder textdata som används för att lära LLM att förstå och generera språk.
- Djupinlärning: En typ av maskininlärning som använder neurala nätverk med många lager för att analysera data.
Arkitekturen bakom LLM: Transformer Modeller
Hjärtat i de flesta moderna LLMs är transformer modellen. Denna arkitektur, introducerad i en uppmärksammad artikel med titeln ”Attention is All You Need”, revolutionerade området för naturlig språkbehandling. Tidigare modeller hade svårt att hantera långa texter och komma ihåg kontexten, men transformer modellen löste detta problem genom att införa en mekanism som kallas ”attention”.
Attention-mekanismen gör det möjligt för modellen att väga olika delar av input-texten när den genererar output. Istället för att bara fokusera på det senaste ordet kan modellen ta hänsyn till alla ord i meningen, vilket ger en bättre förståelse för sammanhanget.
Hur Transformer Modellen Fungerar
- Encoding: Input-texten omvandlas till en numerisk representation.
- Attention: Modellen beräknar vikten av varje ord i förhållande till de andra orden.
- Decoding: Baserat på de beräknade vikterna genereras output-texten.
Transformer modellen är också mycket parallelliserbar, vilket innebär att den kan tränas mycket snabbare än tidigare arkitekturer. Detta är avgörande för att kunna hantera de enorma datamängder som krävs för att träna LLMs.
Hur tränas en LLM?
Träningen av en LLM är en resurskrävande process som involverar stora mängder data och beräkningskraft. Processen kan delas in i två huvudfaser: pre-training och finjustering.
Pre-training
Under pre-training-fasen matas modellen med enorma mängder textdata från olika källor, som till exempel:
- Böcker
- Artiklar
- Webbsidor
- Kod
Modellen lär sig att förutsäga nästa ord i en sekvens. Detta kallas för ”självövervakad inlärning”, eftersom modellen inte behöver några etiketter eller manuell övervakning. Genom att förutsäga nästa ord lär sig modellen att förstå grammatik, ordförråd och den allmänna strukturen i språket.
Finjustering
Efter pre-training-fasen finjusteras modellen för att utföra specifika uppgifter. Detta görs genom att träna modellen på en mindre, mer specifik datamängd som är relevant för den uppgift den ska utföra. Exempel på uppgifter kan vara:
- Frågesvar
- Textgenerering
- Sentimentanalys
Under finjusteringen använder man ”övervakad inlärning”, vilket innebär att modellen tränas på data som är etiketterad med rätt svar. Detta hjälper modellen att lära sig att utföra uppgiften mer exakt och effektivt.
Pre-training och Finjustering
Pre-training och finjustering är två distinkta men kompletterande steg i utvecklingen av LLMs. Pre-training ger modellen en bred förståelse för språket, medan finjustering gör det möjligt för modellen att specialisera sig på specifika uppgifter.
Tänk på det som att lära sig ett nytt språk. Pre-training är som att lära sig grundläggande grammatik och ordförråd, medan finjustering är som att lära sig att skriva en specifik typ av text, som till exempel en roman eller en vetenskaplig artikel.
Användningsområden för LLM
LLMs har en mängd olika användningsområden och potentialen är enorm. Här är några exempel:
- Textgenerering: Skriva artiklar, blogginlägg, e-postmeddelanden, och till och med poesi.
- Översättning: Översätta text mellan olika språk.
- Chatbots: Skapa mer intelligenta och engagerande chatbots för kundtjänst och andra applikationer.
- Frågesvar: Svara på frågor baserat på en given text eller ett kunskapsområde.
- Kodgenerering: Generera kod i olika programmeringsspråk.
- Sammanfattning: Sammanfatta långa texter till kortare, mer koncisa versioner.
Dessa är bara några exempel, och nya användningsområden upptäcks hela tiden. LLMs håller på att revolutionera många branscher, från kundtjänst och marknadsföring till utbildning och forskning.
Utmaningar och Begränsningar med LLM
Trots deras imponerande förmågor finns det fortfarande betydande utmaningar och begränsningar med LLMs:
- Bias: LLMs kan ärva bias från de data de tränas på, vilket kan leda till diskriminerande eller stötande output.
- Hallucinationer: LLMs kan ibland generera falsk eller osann information, även om de är övertygande formulerade.
- Beräkningskostnad: Träning och användning av LLMs kräver betydande beräkningsresurser, vilket gör det dyrt och energikrävande.
- Förståelse: Även om LLMs kan generera imponerande text, är det oklart om de verkligen förstår vad de skriver.
- Etiska frågor: Det finns etiska frågor kring användningen av LLMs, som till exempel risken för desinformation och missbruk.
Forskare och utvecklare arbetar aktivt med att adressera dessa utmaningar och utveckla metoder för att minska bias, förbättra noggrannheten och minska beräkningskostnaderna.
Framtiden för Large Language Models
Framtiden för Large Language Models ser ljus ut. Med fortsatta framsteg inom maskininlärning och AI modeller kan vi förvänta oss att se ännu mer kraftfulla och mångsidiga LLMs i framtiden. Några potentiella utvecklingar inkluderar:
- Större modeller: Med ännu fler parametrar och mer data kan LLMs bli ännu bättre på att förstå och generera språk.
- Effektivare träning: Nya metoder för träning kan minska beräkningskostnaderna och göra det möjligt att träna LLMs snabbare.
- Bättre förståelse: Forskning pågår för att förbättra LLMs förmåga att verkligen förstå språket, snarare än bara att imitera det.
- Nya användningsområden: LLMs kommer sannolikt att användas inom ännu fler områden i framtiden, som till exempel medicin, juridik och vetenskaplig forskning.
Large Language Models har potential att förändra hur vi interagerar med datorer och hur vi kommunicerar med varandra. Det är en spännande tid att följa utvecklingen inom detta område.
Slutsats
Large Language Models (LLMs) representerar ett stort steg framåt inom artificiell intelligens. Genom att förstå deras arkitektur, träningsprocess och potentiella användningsområden kan vi bättre uppskatta deras inverkan på samhället och förbereda oss för framtiden. Medan utmaningar kvarstår, är potentialen för LLMs att transformera olika branscher och förbättra våra liv enorm.
FAQ – Vanliga frågor om LLM
Vad menas med LLM?
LLM står för Large Language Model, vilket är en typ av AI-modell tränad på stora mängder textdata för att förstå och generera mänskligt språk. Dessa modeller använder neurala nätverk, särskilt transformer-arkitekturen, för att bearbeta och producera text.
Vad är en enkel förklaring av LLM?
Tänk dig en dator som har läst hela internet. En LLM är ungefär som det. Den har tränats på enorma mängder text och kan därför förstå och generera text som liknar mänsklig kommunikation. Den kan svara på frågor, skriva texter och översätta språk.
Är ChatGPT en LLM?
Ja, ChatGPT är ett exempel på en LLM. Den är utvecklad av OpenAI och är baserad på GPT-arkitekturen (Generative Pre-trained Transformer), vilket är en typ av transformer-modell. ChatGPT är speciellt utformad för att generera text i en konversationsstil.
Vad är skillnaden mellan LLM och AI?
AI (Artificiell Intelligens) är ett brett område som omfattar alla tekniker som gör det möjligt för datorer att utföra uppgifter som normalt kräver mänsklig intelligens. LLM (Large Language Model) är en *specifik typ* av AI-modell som är specialiserad på att förstå och generera språk. Med andra ord är LLM en underkategori av AI.